Tracking Inter-Object Dependencies using Expression Trees (Part 2)
This is the second part of an article that covers the usage of lambda expressions to monitor changes on complex object graphs. The first part can be found here and the third part (Lambda Binding) is here.
Latest Version: 1.0.3, 2009.04.03
Download Project: lambda-dependencies.zip
Introduction
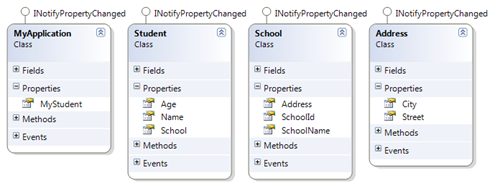
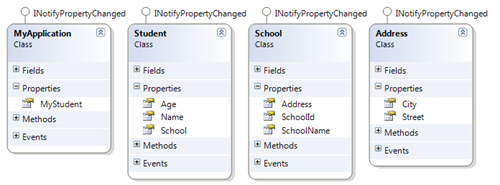
The first part covered the basics of the framework based on a sample application where I monitored any changes on the object graph MyStudent.School.Address.City with a simple lambda expression:
public MyApplication() { //create a dependency on the city of the student's school var dep = DependencyNode.Create(() => MyStudent.School.Address.City); }
The subsequent chapters discuss a few advanced topics that might be important when working with the API.
INotifyPropertyChanged vs. Manual Updates
In order to pick up a changed values on the dependency chain, the observed classes (in the sample: School, Student, Address) must implement the INotifyPropertyChanged interface. Otherwise, changes remain undetected.
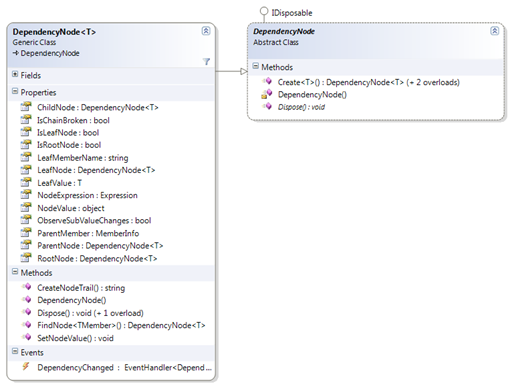
This might not be a problem in case of immutable properties or fields, and it is perfectly valid to include classes that do not implement the interface. However: In case you don’t have INotifyPropertyChanged available (e.g. because you rely on a class in an external library), and changes do occur, you can manually update these node values by invoking the SetNodeValue method of an arbitrary dependency node.
public void SetFieldDependency() { Student student = TestUtil.CreateTestStudent(); //create dependency on the address field rather than the Address property var dep = DependencyNode.Create(() => student.School.address.City); dep.DependencyChanged += (node, e) => Console.WriteLine("City: " + e.TryGetLeafValue()); //exchange address var newAddress = new Address {City = "Stockholm"}; student.School.address = newAddress; //get the node that represents the address var addressFieldNode = dep.FindNode(() => student.School.address); //set the node value manually and trigger change event addressFieldNode.SetNodeValue(newAddress, true); }
Reacting to Sub Property and Target Collection Changes
In the sample above, we declared a dependency on the City property of an Address object. City is just a string, but what if we wanted to track *any* change on the school’s address? One way would be to declare dependencies for every single property of the address:
var student = TestUtil.CreateTestStudent("Harvard"); //create dependency on City var dep1 = DependencyNode.Create(() => student.School.Address.City); //create dependency on Street var dep2 = DependencyNode.Create(() => student.School.Address.Street); //...
This, however, is pretty tedious and there is a simpler solution: As Address implements INotifyPropertyChanged, we can just declare a dependency on the Address property of School.
var student = TestUtil.CreateTestStudent("Harvard"); //create dependency on address object var dep1 = DependencyNode.Create(() => student.School.Address); //output the changed property name and the change reason dep1.DependencyChanged += (node, e) => { string msg = "Changed property: {0}, change reason: {1}"; Console.Out.WriteLine(msg, e.ChangedMemberName, e.Reason); }; //change the city student.School.Address.City = "Ethon";
The above snippet registers with the DependencyChanged event and writes two properties of the event’s DependencyChangeEventArgs to the console: ChangedMemberName and the Reason. This produces the following console output:
Changed property: City, change reason: SubPropertyChanged
Note that this is a special case: The declared dependency chain is Student:School:Address while we received a change event for the City property, which is not part of the dependency chain!
I think that usually, this is a desired behavior, so this is the default. However, you can control this behavior by using a DependencyNodeSettings class and explicitly setting the ObserveSubValueChanges property:
var student = TestUtil.CreateTestStudent("Harvard"); //create settings class var settings = new DependencyNodeSettings<Address>(() => student.School.Address); settings.ChangeHandler = OnDependencyChanged; //configure settings to ignore sub item changes settings.ObserveSubValueChanges = false; //does not cause a change event: Student.School.Address.City = "Ethon";
Note that the same behavior goes for target items that are collections. If the target collection implements the INotifiyCollectionChanged interface, the dependency node fires the DependencyChanged event with a reason of TargetCollectionChange as soon as the contents of the targeted collection changes.
Weak References (and Deserved Credits)
A DependencyNode only maintains weak references. Even if it would not pick up an object that goes out of scope because no property change event was fired, this still wouldn’t stop the targeted object from being garbage collected. The same goes for node’s events and internal event listeners.
I’m using two very nice implementations for internal listeners and the exposed DependencyChanged event:
- Daniel Grunwald’s FastSmartWeakEvent
- Paul Stovell’s WeakEventProxy, which is part of his Bindable LINQ project.
Limitations
This library solves a specific problem and currently operates solely on members, variables, and constant expressions – more complex expressions (such as LINQ queries) are currently out of the picture, but I’m open to suggestions. You might also look out for related projects, such as Bindable LINQ.